
زبان برنامه نویسی پایتون (Python)
آشنایی با زبان برنامه نویسی پایتون و کاربردهای آن 🚀 پایتون یک زبان برنامه نویسی…
بیشتر بخوانید

ماشین لرنینگ (Machine Learning) در واقع یکی از تخصصهای شاخه هوش مصنوعی است. این فناوری توانایی این را به سیستمها و کامپیوترها میدهد تا بدون اینکه به برنامه نویسی نیاز داشته باشند، مستقیماً از دادهها یاد بگیرند. ماشین لرنینگ امروزه دارای نقش اساسی در صنایع مختلف است و هر روز که میگذرد، اهمیت آن بیش از قبل میشود، چرا که این علم رشد بسیار فزایندهای دارد.
مشاهده دوره آموزشی هوش مصنوعی
یادگیری ماشین (Machine Learning) فرآیندی است که در آن الگوریتمها با تحلیل دادهها و شناسایی الگوهای پنهان در آنها، قادر به پیشبینی و تصمیمگیری میشوند. این مدلهای ریاضی به سیستمها اجازه میدهند تا بدون برنامهنویسی صریح، از تجربهها یاد بگیرند و عملکرد خود را بهبود دهند.
برای مثال، یک مدل ماشین لرنینگ میتواند رفتار یک دستگاه صنعتی را که وظیفه چسباندن بارکد روی محصولات را دارد، بررسی کرده و الگوی دقیق این عملکرد را یاد بگیرد. سپس با اعمال این الگوها به حافظه دستگاه، فرآیند بارکدزنی را بهطور کاملاً خودکار، با دقتی مشابه یا حتی بیشتر از نیروی انسانی انجام دهد.
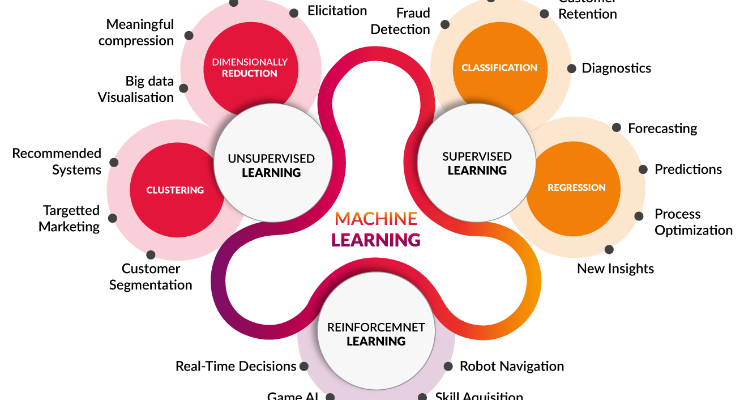
Machine Learning سه دسته اصلی دارد:
یادگیری نظارتشده (Supervised Learning)
دادههای آموزشی دارای برچسب هستند. مدل با استفاده از این دادهها یاد میگیرد. مثال: پیشبینی نرخ ارز.
یادگیری بدون نظارت (Unsupervised Learning)
در این نوع یادگیری ماشین، دادهها برچسب ندارند و مدل بهدنبال یافتن الگوهاست. مثال: زیر مجموعه ساختن از لیست مشتریان. (خوشهبندی)
یادگیری تقویتی (Reinforcement Learning)
این مدل با سیستم پاداش و بازخورد، بهترین روشها را برای انجام کار پیدا میکند. مثال: آموزش رباتها.
جهت دریافت اطلاعات بیشتر درمورد دورهها و اساتید با مشاورین دوران آکادمی در ارتباط باشید.
ماشین لرنینگ در زمینههای متعددی کاربرد دارد از جمله میتوان به موارد زیر اشاره کرد:
تشخیص بیماریها و تحلیل دادههای ژنتیکی.
اتوماتیکسازی تولیدات و پیشبینی مواردی که نیاز به تعمیر دارند.
پیشبینی فروش و شخصیسازی تبلیغات.
بهینهسازی مسیرها و توسعه اتومبیلهای بدون راننده.
مدیریت سرمایه و تشخیص تقلبها و کلاهبرداریها.
طراحی و ایجاد دورههای آموزشی شخصیسازی شده.
برای آموزش زبان های برنامه نویسی به صورت تخصصی دوران آکادمی بهترین گزینه است.
مشاهده دوره های برنامه نویسی
پایتون از مرسومترین و پرطرفدارترین زبانها برای اجرای پروژههای ماشین لرنینگ است. این زبان دارای کتابخانههایی برای این کار است. از جمله آنها میتوان اشاره کرد به:
برای مدلهای پایهای.
برای یادگیری عمیق.
برای پروژههای پیشرفته.
شروع یادگیری Machine Learning با پایتون بسیار ساده است. شما میتوانید در آموزشهای آنلاین و پروژههای عملی مشارکت کنید. بکارگیری پایتون بهخاطر ساده بودن سینتکس و پشتیبانی وسیع از منابع آموزشی، برای علاقهمندان توصیه میشود.
ماشین لرنینگ مهارتی اساسی و مهم در آیتی است. یادگیری آن در حال حاضر میتواند برای شما فرصتهای شغلی بیشماری را بهوجود آورد. متخصصان ماشین لرنینگ تقاضای بالایی در بین صاحبان مشاغل دارند. بهعلاوه، این حوزه شما را قادر میسازد تا در پروژههای نوآورانه شرکت کنید و در پیشرفت فناوری ایفای نقش کنید.
برای شروع مهارت یادگیری ماشین، باید موارد زیر را در نظر داشته باشید:
دورههای مانند دوره Machine Learning و دوره هوش مصنوعی دوران آکادمی منابع دورههای آموزشی مناسبی هستند. این دورهها مباحثی مانند پردازش دادهها، ساخت مدلها و ارزیابی عملکرد آنها هستند.
همانطور که گفتیم Machine Learning زیر مجموعهای از AI است:
خلق سیستمهایی که مانند انسان فکر میکنند.
این دو فناوری در کنار هم آیندهای هوشمندتر را پدید خواهند آورد. ترکیب این دو فناوری در زمینههایی از قبیل سلامت، آموزش، تولید و تجارت و… تحولهای بزرگی را رقم خواهند زد.
در یادگیری Machine Learning ممکن است با سختیهای زیر مواجه شوید:
کیفیت دادههایی که جمعآوری میکنیم تاثیر مستقیمی بر دقت مدل دارد
انتخاب بهترین الگوریتم و پارامترها از کارهای سخت و زمانبر در این مورد است
بعضی از مفاهیم شاید برای افراد مبتدی، دشوار باشند
هرچند با تلاش بیشتر و تمرین یا شرکت در دورههای آموزشی معتبر، این چالشها برای شما تا حدودی ساده حواهند شد.
ماشین لرنینگ در حال ایجاد دگرگونی بزرگ در جهان است. این فناوری نه فقط در صنایع، حتی در زندگی روزمره ما هم تاثیرگذار است. آموزشهای آن به شما دیدگاهی نوین از قدرت دادهها و هوش مصنوعی خواهد داد. اگر درپی راهی هستید که بتوانید در آن با تحلیل دادهها، فناوریهای نوآورانه را خلق کنید و حتی در حل مسائل پیچیده تاثیر بسزایی داشته باشید، Machine Learning انتخاب اول شما خواهد بود. این فناوری بیش از آنچه در حال حاضر در موفقیت شما موثر باشد، آینده درخشانی خواهد داشت. امروز قدم بردارید و از آموزشهای دوران آکادمی برای آینده خود بهره ببرید.
بیشتر بخوانید :
آشنایی با زبان برنامه نویسی پایتون و کاربردهای آن 🚀 پایتون یک زبان برنامه نویسی…
بیشتر بخوانید

🧐 یک بررسی اساسی؛ فرق #C و C++ در چیست؟ اگر وارد دنیای برنامهنویسی شده…
بیشتر بخوانید

کاربردهای فوقالعاده جنگو که هر برنامهنویسی باید بداند!✅ جنگو (Django) یکی از محبوبترین فریمورکهای توسعه…
بیشتر بخوانید

چگونه جنگو را نصب کنیم؟ آموزش کامل و ساده برای مبتدیان جنگو (Django) یکی از…
بیشتر بخوانید

می خواهید برنامه نویس شوید؟ با این اپلیکیشن ها شروع کنید! 💻 برنامه نویسی یکی…
بیشتر بخوانید

۵ راه برای عبور از موانع برنامه نویسی 👨💻 یادگیری کدنویسی میتواند چالشبرانگیز باشد. افراد…
بیشتر بخوانید



